Advanced Engineering Informatics • Volume 65 • 2025 • Article 103297
Aprendizaje por refuerzo contrastivo continuo (CCRL)
Hacia un agente más sólido y consciente del entorno para el diagnóstico de fallos en motores aeronáuticos comerciales mediante optimización a largo plazo en escenarios altamente desbalanceados.
Autores
Haoze Wu; Shisheng Zhong; Minghang Zhao; Xuyun Fu; Yongjian Zhang; Song Fu
Afiliaciones
- a. School of Mechatronics Engineering, Harbin Institute of Technology, Harbin 150001, China
- b. Department of Mechanical Engineering, Harbin Institute of Technology, Weihai 264209, China
- c. Weihai Key Laboratory of Intelligent Operation and Maintenance, Harbin Institute of Technology, Weihai 264209, China
Idea central
El aprendizaje por refuerzo contrastivo continuo (CCRL) combina un diseño de recompensas sensible al desequilibrio en el aprendizaje por refuerzo con aprendizaje contrastivo de representaciones que no depende de la generación de muestras sintéticas. Al aumentar el peso de la recompensa para estados de fallo poco frecuentes, el agente mantiene la atención sobre patrones críticos durante la interacción en línea y la actualización incremental, y se adapta a las variaciones de fase y condición de operación del motor. A la vez, la función de pérdida contrastiva se ajusta para explotar plenamente los datos temporales desbalanceados existentes, logrando el objetivo de ampliar la separación interclase y compactar la variabilidad intraclase sin introducir muestras artificiales.
CCRL en breve
Para el diagnóstico de fallos de motores aeronáuticos en escenarios altamente desbalanceados, CCRL integra un agente impulsado por aprendizaje contrastivo dentro de un marco D3QN. Mediante la distinción de características sin generación de muestras y un mecanismo de recompensa consciente del desequilibrio, logra un reconocimiento de fallos estable y eficaz, validado en escenarios reales de diagnóstico y en estudios de ablación.
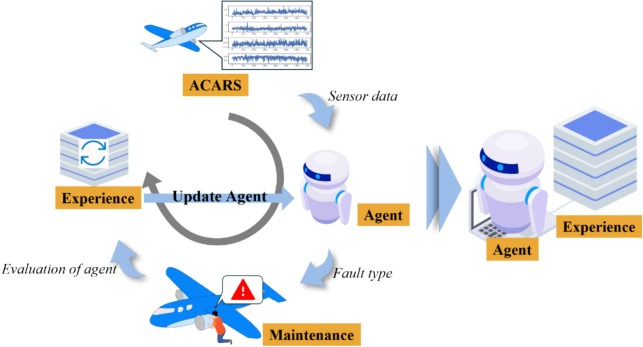
Problema
El diagnóstico de fallos de motores aeronáuticos afronta desequilibrios severos de clase, muestras de fallo muy escasas y entornos operativos no estacionarios. Los métodos contrastivos tradicionales dependen de aumentos de datos, sin garantía de consistencia física en series temporales.
Idea
Reforzar la discriminación de características mediante aprendizaje contrastivo y combinarla con D3QN con diseño de recompensas desbalanceadas para reconocer de forma estable fallos raros.
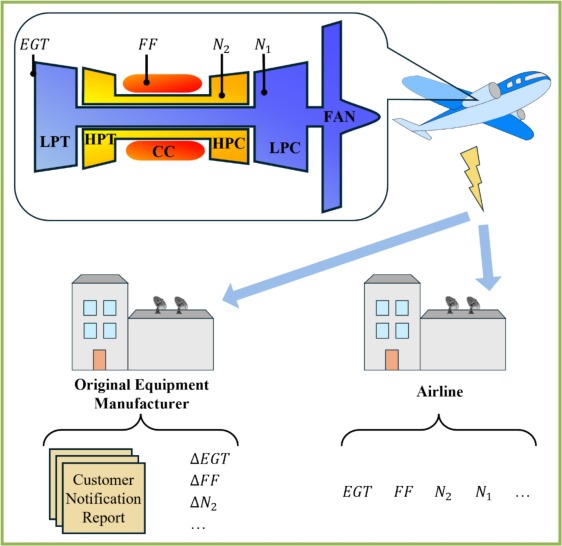
Datos de entrada
ΔEGT (desviación de temperatura de gases de escape), ΔN2 (desviación de velocidad del núcleo), ΔFF (desviación de flujo de combustible) y N1 (velocidad del fan) medidos en el despegue.
Tipos de fallo
Fallo del sistema VBV, fallo EGTI, fallo del sensor TAT y vuelos normales.
Visión general
Resumen
Los fallos de motores aeronáuticos son poco frecuentes pero pueden provocar consecuencias catastróficas. Los métodos de diagnóstico basados en datos suelen apoyarse en pocas muestras históricas de fallos y no logran actualizar los modelos a tiempo cuando cambian las condiciones o crece el volumen de datos. CCRL integra interacción con el entorno y evolución continua para abordar el diagnóstico de fallos bajo desequilibrio extremo y datos en crecimiento. El entorno operativo de la aerolínea se modela como entorno de aprendizaje; los datos de vuelo son el estado y las etiquetas proceden de la identificación de fallos confirmada por expertos. Con abundantes muestras normales se preentrena un codificador basado en autodecodificador LSTM, y se afina con pares positivos y negativos reales bajo una pérdida contrastiva ponderada para escenarios desbalanceados. Posteriormente, el codificador se incrusta en el modelo de refuerzo para mejorar la percepción del entorno y la capacidad de diferenciación de fallos. Experimentos comparativos y de ablación con datos reales validan el potencial de la metodología en aplicaciones de ingeniería.
Conceptos clave
Información del artículo
- Título
- Aprendizaje por refuerzo contrastivo continuo: hacia un agente más fuerte para el diagnóstico de fallos de motores aeronáuticos con percepción del entorno mediante optimización a largo plazo en escenarios altamente desbalanceados
- Revista
- Advanced Engineering Informatics
- Código
- GitHub: haozewu/ccrl
- PyPI
- ccrl
- Palabras clave
- Diagnóstico de fallos de motores aeronáuticos; Aprendizaje por refuerzo contrastivo continuo; Percepción del entorno; Crecimiento de datos de monitorización
Relevancia práctica
- Diseñado para operaciones reales de aerolíneas, permite actualizar continuamente el modelo a medida que llegan nuevos datos de vuelo.
- Aborda el desequilibrio extremo de clases sin generar series temporales sintéticas.
- Mejora la representación discriminativa de fallos raros mediante aprendizaje contrastivo ponderado.
- El modelado de recompensas desbalanceadas mejora la decisión para categorías de fallo de cola larga.
Método
CCRL combina un módulo de distinción de características (aprendizaje contrastivo con preentrenamiento de autoencoder) y un módulo de identificación de tipo (D3QN con recompensas desbalanceadas) en una canalización integral que puede actualizarse de forma continua.
1) Bucle de aprendizaje continuo con percepción del entorno
El proceso operativo de la aerolínea se considera un entorno. Tras cada vuelo, los datos de sensores se transmiten vía ACARS y se almacenan. El agente predice el tipo de fallo, se evalúa frente a resultados confirmados por expertos y aprende de manera continua de la biblioteca de experiencias en expansión, logrando optimización a largo plazo.
2) Módulo de distinción de características
En lugar de depender de aumentos de series temporales, CCRL construye pares positivos con muestras reales del mismo tipo de fallo y pares negativos con tipos diferentes. Para aliviar la escasez de fallos, el codificador se preentrena con un autoencoder LSTM sobre abundantes muestras normales y luego se ajusta bajo una pérdida contrastiva ponderada para aprender representaciones discriminativas en escenarios altamente desbalanceados.
3) Módulo de identificación de tipo
El codificador contrastivo congelado alimenta a un Dueling Double Deep Q-Network (D3QN). Las recompensas se escalan por la frecuencia inversa de la clase para enfatizar fallos raros (clases de cola larga), mejorando el reconocimiento en condiciones desbalanceadas. El entrenamiento usa repetición de experiencias y red objetivo para un aprendizaje Q estable.
Evolución del aprendizaje contrastivo para diagnóstico de fallos
En el marco SimCLR tradicional, el aprendizaje contrastivo depende de aumentos de datos para construir pares positivos. En series temporales de motores aeronáuticos no existe garantía teórica de que tales aumentos preserven las características físicas de los fallos. Este trabajo extiende la pérdida autosupervisada estándar hacia una pérdida contrastiva ponderada y consciente del desequilibrio, adaptada al diagnóstico altamente desbalanceado.
Limitación: Trata el resto de muestras como negativos equivalentes y asume un conjunto equilibrado, haciendo que el modelo pase por alto fallos raros del motor.
Optimización: Introduce para reforzar la agrupación de fallos raros y para reducir la interferencia de clases dominantes como "Normal".
Notas sobre símbolos
- Factor de escala de temperatura para los logits de similitud.
- Similitud coseno entre vectores latentes z_i y z_j.
- Peso de pares positivos para enfatizar fallos raros.
- Peso de pares negativos para atenuar clases dominantes (por ejemplo, Normal).
- Número de pares de anclaje positivos en un lote.
Detalles técnicos de implementación:
- Consistencia física: Se emparejan muestras reales distintas del mismo tipo de fallo, en lugar de aumentos sintéticos, para que el modelo aprenda patrones reales de sensores.
- Preentrenamiento del codificador: Se entrena primero un autoencoder LSTM con abundantes datos normales para capturar la dinámica base del motor, antes de ajustar con la pérdida ponderada.
- Distinción de características: Al establecer pesos adecuados, el modelo prioriza la separación de categorías de fallo altamente desbalanceadas (VBV, EGTI, TAT).
Diagrama del módulo de distinción de características
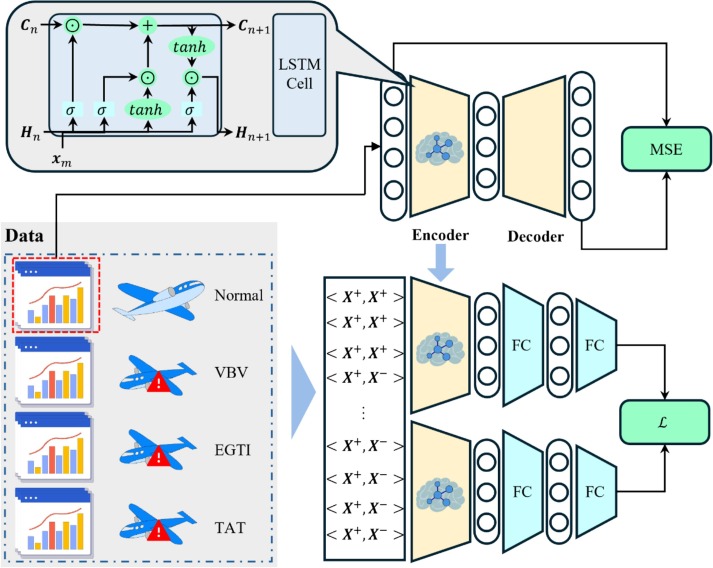
Fig. 3: Preentrenamiento con autoencoder y flujo de aprendizaje contrastivo ponderado.
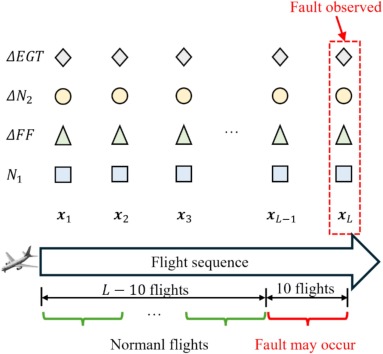
Señales y tipos de fallo
Entradas
ΔEGT, ΔN2, ΔFF y N1 en una ventana de 10 vuelos (serie temporal).
Clases
Normal, fallo del sistema VBV, EGTI, fallo del sensor TAT.
Objetivo de despliegue
Diagnóstico robusto de motores aeronáuticos bajo desequilibrio extremo de clases, con adaptación continua a entornos operativos en evolución.
Resultados
Se compara CCRL con D3QN y variantes con submuestreo (DS) y sobremuestreo (OS) bajo divisiones aleatorias repetidas. El objetivo principal es lograr un diagnóstico robusto de motores aeronáuticos bajo desequilibrio extremo de clases; la adaptación continua es una capacidad secundaria.
F1 global
84.26 ± 4.62
Mejor F1 global en ejecuciones repetidas.
Precisión
87.19 ± 4.34
Menos falsas alarmas en condiciones desbalanceadas.
Recall
84.00 ± 4.77
Mayor capacidad para reconocer clases minoritarias.
Qué se validó
- Diagnóstico desbalanceado: la clasificación de fallos de cola larga es el reto central.
- Sin muestras extra: mejora sin incrementar la cantidad de datos.
- Estabilidad: menor varianza en divisiones aleatorias repetidas.
- Validez de la arquitectura: los estudios de ablación confirman la racionalidad de cada módulo propuesto.
Configuración experimental
Tarea
Diagnóstico multiclase de fallos de motores aeronáuticos bajo desequilibrio severo (fallos de cola larga vs. abundantes normales).
Métodos base
D3QN, DS + D3QN, OS + D3QN (divisiones aleatorias repetidas).
Métricas
F1, precisión, recall (media ± desviación típica), enfatizando el rendimiento en clases minoritarias.
Conclusión clave
Mejor separabilidad de fallos y aprendizaje de decisiones bajo desequilibrio extremo; la evolución continua es secundaria.
Tabla de resultados
| Método | F1 (media ± dt) | Precisión (media ± dt) | Recall (media ± dt) |
|---|---|---|---|
| D3QN | 77.19 ± 3.81 | 80.71 ± 4.15 | 76.75 ± 3.88 |
| DS + D3QN | 68.15 ± 9.26 | 71.05 ± 9.10 | 68.00 ± 9.14 |
| OS + D3QN | 74.38 ± 5.07 | 81.20 ± 3.66 | 74.00 ± 4.90 |
| CCRL | 84.26 ± 4.62 | 87.19 ± 4.34 | 84.00 ± 4.77 |
Interpretación: el submuestreo reduce el rendimiento por pérdida de información; el sobremuestreo mejora el recall pero es menos estable; CCRL logra el mejor equilibrio.
Conclusiones clave
- CCRL mejora notablemente el reconocimiento de fallos minoritarios sin aumentar la cantidad de muestras.
- Una precisión mayor implica menos falsas alarmas en el despliegue operativo.
- La menor variabilidad indica mayor robustez frente a divisiones aleatorias.
Hallazgos de ablación
- Aprendizaje contrastivo de características fortalece la separabilidad de clases bajo desequilibrio.
- Recompensas sensibles al desequilibrio estabilizan el aprendizaje de decisión para fallos raros.
- Flujo completo el marco CCRL completo alcanza el mejor rendimiento y estabilidad.
Dinámica de entrenamiento
CCRL muestra convergencia más suave y progresión de recompensas más estable frente a las variantes DS/OS.
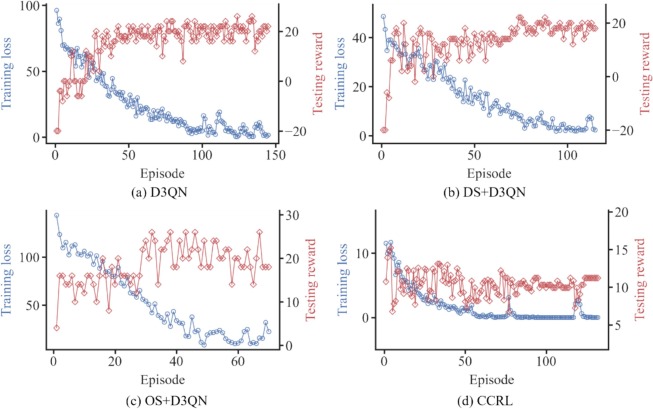
Fig. 12: Pérdida de entrenamiento y recompensas de prueba para cada método.
Patrones de error
Las matrices de confusión muestran cómo las líneas base confunden fallos raros con estados normales, mientras CCRL mitiga este modo de fallo.
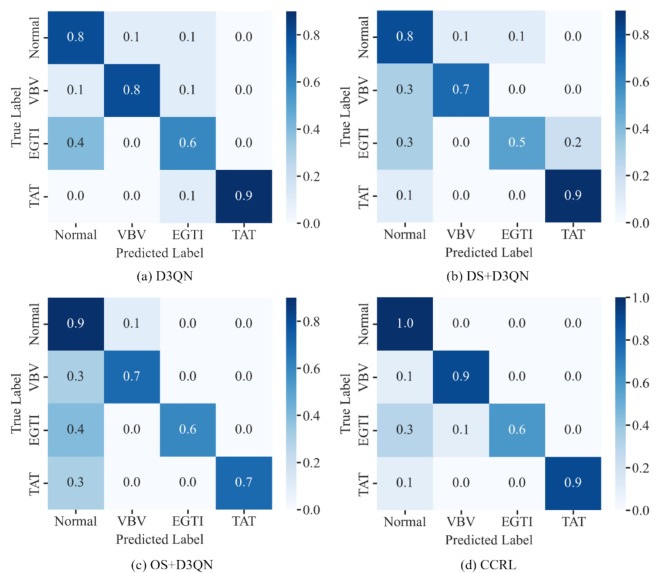
Fig. 15: Matrices de confusión que muestran dónde se confunden fallos raros con normales.
Figuras rápidas
Impacto y citas
Trabajos representativos que citan o se alinean conceptualmente con esta investigación.
Advanced Engineering Informatics
Método de aumento de datos para diagnóstico de fallos que integra una red generativa adversaria de difusión multimodal no gaussiana con eliminación de ruido
En entornos industriales reales, la obtención de datos de fallos es mucho más difícil que la de estados saludables; las muestras pequeñas y el fuerte desequilibrio de clases son retos centrales en diagnóstico.
Energy
Método de propagación y evolución en grafos con restricciones físicas para diagnóstico profundo de fallos multifactor en motores aeronáuticos
Wu et al. combinaron aprendizaje por transferencia profunda, aprendizaje por refuerzo y aprendizaje por refuerzo contrastivo continuo para el diagnóstico de fallos y la optimización de estrategias de mantenimiento en motores aeronáuticos.
Mathematics
Diagnóstico de fallos de bomba de combustible aeronáutica basado en un autoencoder variacional condicional y mejora adaptativa de datos escasos
El desequilibrio de clases sesga los modelos supervisados hacia las clases mayoritarias, generando baja detección de minorías, alta tasa de falsas alarmas y fronteras de decisión poco claras.
Measurement
Estrategia de alineación de características y adaptación de dominio espaciotemporal para construir sensores virtuales de motores aeronáuticos bajo desplazamientos de dominio
Wu et al. propusieron un marco robusto de modelado sustituto para entornos de datos altamente desbalanceados, con énfasis en adaptación de dominio y alineamiento de representaciones.
IEEE Transactions on Instrumentation and Measurement
Marco eficaz para diagnóstico de fallos de cajas de engranajes entre condiciones con clases desbalanceadas
Al incrustar aprendizaje contrastivo en el aprendizaje por refuerzo, el agente percibe mejor los cambios del entorno y mejora la robustez diagnóstica bajo desequilibrio de clases.
Journal of Mechanical Engineering and Sciences
Desarrollo de un controlador inteligente de motor a reacción mediante una técnica de gradiente de política determinista profunda basada en modelos
Las técnicas de refuerzo, incluido el aprendizaje contrastivo continuo y el filtrado adaptativo, refuerzan la detección de fallos en motores aeronáuticos durante fases de alto desequilibrio y cambios súbitos de operación.
Citación
Si este trabajo te resulta útil, por favor cita el artículo.
BibTeX
@article{wu2025ccrl,
title = {Continual contrastive reinforcement learning: Towards stronger agent for environment-aware fault diagnosis of aero-engines through long-term optimization under highly imbalance scenarios},
author = {Wu, Haoze and Zhong, Shisheng and Zhao, Minghang and Fu, Xuyun and Zhang, Yongjian and Fu, Song},
journal = {Advanced Engineering Informatics},
volume = {65},
pages = {103297},
year = {2025},
doi = {10.1016/j.aei.2025.103297},
url = {https://doi.org/10.1016/j.aei.2025.103297}
}Contacto
Para colaboraciones, consultas o solicitudes de reproducibilidad, contacta con los autores corresponsales.
Correo de contacto
Shisheng Zhong: zhongss#hit.edu.cnMinghang Zhao: zhaomh#hit.edu.cn
Agradecimientos
Financiado por el Programa Clave de I+D de China (2023YFB4302400).