Neurocomputing • Volume 649 • 2025 • Article 130876
Estimateur de récupération contrainte des données non observées (CUR-Estimator)
Vers une imputation fiable des données manquantes pour le processus de dégradation des moteurs aéronautiques commerciaux
Auteurs
Haoze Wu; Shisheng Zhong; Minghang Zhao; Xuyun Fu; Yongjian Zhang; Song Fu
Affiliations
- a. School of Mechatronics Engineering, Harbin Institute of Technology, Harbin 150001, China
- b. Department of Mechanical Engineering, Harbin Institute of Technology, Weihai 264209, China
- c. Weihai Key Laboratory of Intelligent Operation and Maintenance, Harbin Institute of Technology, Weihai 264209, China
Idée centrale
L’Estimateur de récupération contrainte des données non observées (CUR-Estimator) vise à améliorer la précision et la stabilité de l’imputation en présence de longues séquences consécutives manquantes dans les données de dégradation du cycle de vie des moteurs aéronautiques. La méthode renforce l’imputation multi-étapes conventionnelle selon deux axes complémentaires. Premièrement, les informations d’intervalle temporel associées aux segments manquants sont explicitement intégrées à la modélisation multivariée des séries temporelles, atténuant l’accumulation d’erreurs due à l’échantillonnage irrégulier et aux prédictions récursives. Deuxièmement, des résultats d’interpolation statistique sont introduits comme a priori distributionnels lors de l’entraînement du réseau neuronal, imposant des contraintes souples aux sorties d’imputation multi-étapes sans recourir à des bornes rigides, ce qui supprime la dérive de prédiction et produit des résultats plus stables et physiquement plausibles.
CUR-Estimator en un coup d’œil
Pour les segments manquants consécutifs dans les données opérationnelles des moteurs aéronautiques, les méthodes d’imputation fondées sur la prédiction mono-étape souffrent souvent d’une accumulation d’erreurs lors des prédictions multi-étapes. CUR-Estimator intègre une modélisation temporelle sensible aux intervalles dans l’imputation neuronale et supprime les dérives de prédiction irréalistes via des contraintes d’interpolation statistique. L’efficacité de la méthode est validée sur des données simulées de moteurs, des jeux de données réels de moteurs civils et des données d’éoliennes.
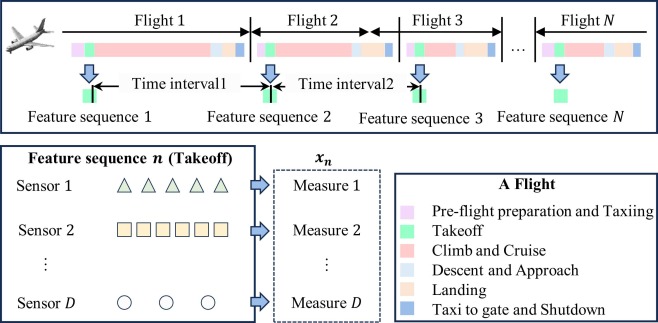
Problème
Les données issues des capteurs des moteurs aéronautiques contiennent inévitablement des valeurs manquantes et du bruit. En présence de segments manquants consécutifs sur l’axe temporel, les stratégies d’imputation basées sur la prédiction mono-étape reposent fortement sur des prévisions récursives, dont les erreurs s’accumulent et s’amplifient à mesure que l’horizon de prédiction augmente. Les méthodes supposant des intervalles d’échantillonnage uniformes peinent à caractériser de manière stable les trajectoires de dégradation et peuvent produire des résultats d’imputation peu plausibles.
Approche
Un réseau GRU renforcé par auto-attention modélise explicitement les intervalles d’échantillonnage irréguliers afin de permettre une imputation sensible aux intervalles. Des résultats d’interpolation statistique sont en outre introduits comme contraintes souples pour limiter l’amplitude numérique des prédictions neuronales, améliorant ainsi la stabilité et la plausibilité physique.
Données d’entrée
Mesures issues des capteurs collectées lors de phases de vol clés, notamment le décollage, la croisière et l’atterrissage.
Caractéristiques clés
Modélisation des intervalles temporels, architecture basée sur GRU et mécanisme d’imputation sous contraintes statistiques.
Vue d’ensemble
Résumé
L’imputation des données manquantes dans les séries temporelles de dégradation du cycle de vie des moteurs aéronautiques fait face à deux défis majeurs. Premièrement, les missions de vol diffèrent en durée, et même une même phase de vol peut varier d’une mission à l’autre, ce qui conduit à des intervalles d’échantillonnage non uniformes. Cette hétérogénéité temporelle complique l’évaluation de l’impact d’un vol individuel sur l’évolution des performances à long terme. Deuxièmement, les méthodes d’imputation basées sur les réseaux neuronaux sont sensibles au bruit important et aux longues séquences manquantes consécutives, ce qui peut entraîner des résultats de récupération non raisonnables. Pour relever ces défis, cet article propose un Estimateur de récupération contrainte des données non observées (CUR-Estimator) pour l’imputation des données manquantes dans les processus de dégradation des moteurs aéronautiques. Les informations d’intervalle temporel sont encodées via une unité récurrente à portes renforcée par Transformer et combinées avec des masques de données manquantes afin d’ajuster les états cachés et les pondérations d’entrée pour les segments manquants, formant ainsi un réseau d’imputation temporelle sensible aux intervalles. Des méthodes d’interpolation statistique sont ensuite utilisées pour contraindre les sorties d’imputation neuronale et en limiter la plage plausible. À titre d’exemple représentatif, le polynôme d’interpolation cubique de Hermite par morceaux (PCHIP) est adopté pour réguler le comportement d’imputation du réseau sensible aux intervalles. Les résultats expérimentaux obtenus sur des jeux de données simulés et des jeux de données réels de moteurs aéronautiques civils démontrent que la méthode proposée atteint une précision élevée d’imputation et une forte stabilité.
Concepts clés
Informations sur l’article
- Titre
- CUR-Estimator (CUR-E): Towards Reliable Missing Data Imputation for Aero-Engine Degradation Process
- Revue
- Neurocomputing
- PyPI
- cur-estimator
- Mots-clés
- Dégradation des moteurs aéronautiques ; Imputation de données manquantes ; Mécanisme d’auto-attention ; Unité récurrente à portes (GRU) ; Contraintes statistiques
Pertinence pratique
- Caractérise efficacement l’hétérogénéité temporelle induite par des intervalles d’échantillonnage irréguliers dans les données de dégradation des moteurs aéronautiques, fournissant une base plus fiable pour la modélisation de l’état de santé sur le cycle de vie.
- S’adapte aux intervalles d’échantillonnage incohérents et aux variations importantes de durée de mission sans nécessiter d’alignement temporel strict, améliorant la précision d’imputation pour les données opérationnelles industrielles.
- Contraint les sorties d’imputation neuronale par interpolation statistique, réduisant le risque de valeurs de récupération anormales en présence de longues séquences manquantes ou de bruit intense.
Méthode
CUR-Estimator aborde l’imputation des données manquantes dans les processus de dégradation des moteurs aéronautiques en introduisant un mécanisme sensible aux intervalles temporels. Fondée sur une architecture GRU et combinée à des contraintes statistiques, la méthode traite efficacement l’échantillonnage irrégulier et les observations manquantes.
1) Imputation sensible aux intervalles temporels
Afin de gérer les intervalles d’échantillonnage irréguliers et les variations de durée des phases de vol dans les données opérationnelles des moteurs aéronautiques, les informations d’intervalle temporel sont explicitement encodées et intégrées au processus de modélisation séquentielle. En combinant une GRU renforcée par auto-attention, le modèle équilibre de manière adaptative les observations historiques et les entrées courantes lors de la mise à jour des états cachés, maintenant une représentation stable de la dégradation en présence de segments manquants consécutifs et de variations d’échelle temporelle, et atténuant l’accumulation d’erreurs causée par le désalignement temporel.
2) Raffinement statistique et contraintes
Pour éviter des résultats d’imputation non raisonnables en présence de longues séquences manquantes ou de bruit important, des méthodes d’interpolation statistique sont introduites afin de contraindre les séquences prédites. En prenant comme exemple le polynôme d’interpolation cubique de Hermite par morceaux (PCHIP), ses propriétés de préservation de la monotonie et de contrainte locale de forme sont exploitées pour construire des plages de valeurs plausibles, supprimant la dérive de prédiction sans imposer de bornes rigides explicites et améliorant la stabilité ainsi que la cohérence physique.
Combinaison des réseaux neuronaux et des contraintes statistiques
Le réseau GRU sensible aux intervalles modélise les dépendances temporelles et les variations d’échelle dans les séries temporelles de dégradation, tandis que l’interpolation statistique fournit des contraintes au niveau de la forme et de la distribution sur les résultats d’imputation, renforçant la stabilité et la plausibilité dans des scénarios complexes de données manquantes.
Détails clés de l’implémentation :
- Encodage des intervalles temporels : Chaque point de données intègre explicitement l’intervalle temporel correspondant, permettant au modèle de percevoir l’hétérogénéité temporelle induite par l’échantillonnage irrégulier et les segments manquants consécutifs lors de la mise à jour des états cachés.
- Guidage par contraintes statistiques : L’interpolation PCHIP est utilisée comme référence statistique pour construire des plages d’imputation plausibles et supprimer les prédictions non raisonnables dans les intervalles manquants prolongés.
- Stratégie d’entraînement intégrée : En introduisant des contraintes guidées par l’interpolation statistique au cours de l’entraînement, le modèle maintient des distributions prédictives stables dans les scénarios d’imputation récursive multi-étapes, réduisant l’accumulation d’erreurs et la dérive de prédiction.
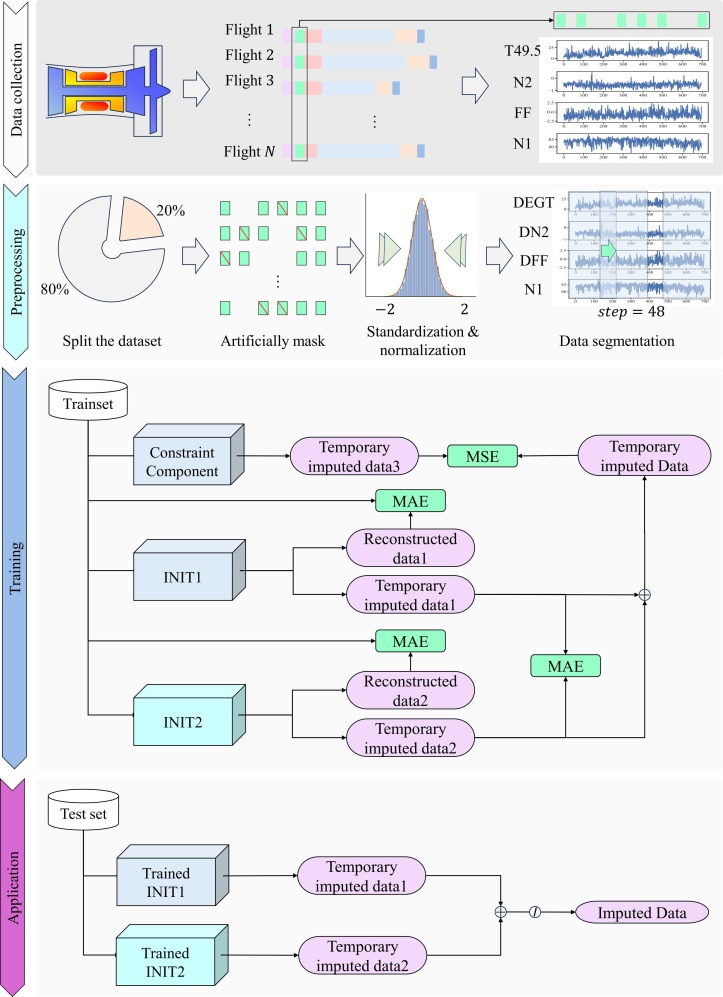
Schéma du flux de travail du cadre
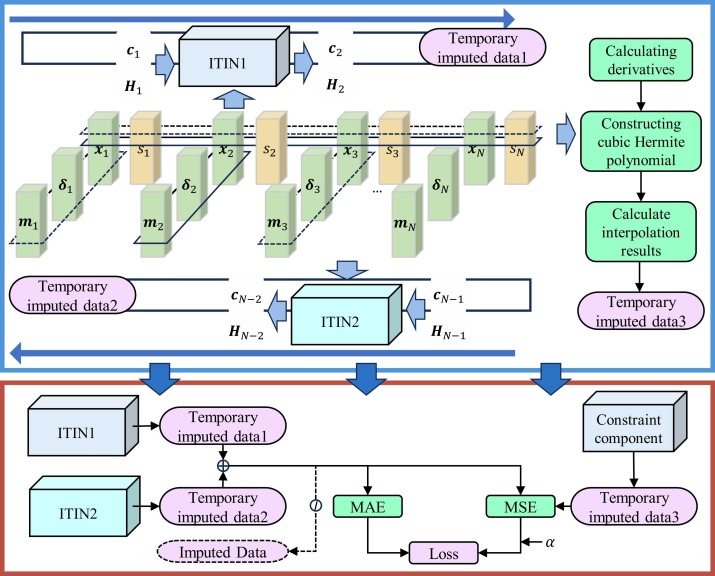
Fig. 4. Flux d’exécution des modules de base. Le cadre correspond à un réseau INIT bidirectionnel, et le résultat final est conjointement déterminé par deux réseaux neuronaux et une méthode d’interpolation.
Entrées de données et contraintes
Entrées
Données de performance de vol, lectures des capteurs, intervalles temporels et masques de données manquantes.
Contraintes
L’interpolation cubique de Hermite par morceaux (PCHIP) est utilisée pour contraindre l’intervalle de valeurs imputées.
Objectif de déploiement
Imputation de haute précision pour l’analyse réelle de la dégradation des moteurs aéronautiques.
Résultats
Évalué sur des tâches d’imputation des données de dégradation des moteurs aéronautiques, avec un accent particulier sur la précision et la stabilité de l’imputation dans des conditions d’intervalles d’échantillonnage irréguliers.
Erreur moyenne d’imputation
0.0717 ± 0.0022
Meilleure erreur globale d’imputation obtenue sur des expériences répétées.
Stabilité de l’imputation
0.0022
Variabilité plus faible des résultats sous des intervalles d’échantillonnage irréguliers.
Précision de récupération des données
89.57 ± 3.71
Capacité de récupération plus élevée par rapport aux méthodes de référence.
Éléments validés
- Précision de l’imputation: Amélioration significative de la précision de récupération des valeurs manquantes dans les séries temporelles de dégradation des moteurs aéronautiques.
- Gestion des intervalles irréguliers: Capacité à s’adapter efficacement aux variations des intervalles temporels entre les lectures des capteurs.
- Robustesse: Maintien d’une faible variance sur des expériences répétées.
- Applicabilité inter-scénarios: Validé par des expériences comparatives sur un jeu de données d’éoliennes.
Configuration expérimentale
Tâche
Imputation des données manquantes pour des séries temporelles de dégradation multi-classes de moteurs aéronautiques avec des intervalles d’échantillonnage irréguliers.
Méthodes de référence
GRU, GRU + contraintes statistiques et méthodes traditionnelles d’imputation de séries temporelles.
Indicateurs d’évaluation
Erreur moyenne d’imputation, précision de récupération et stabilité (moyenne ± écart-type), avec un accent particulier sur la récupération dans des conditions difficiles.
Conclusion clé validée
Amélioration de la stabilité et de la précision sans augmentation de la taille de l’échantillon, soutenant une amélioration continue.
Tableau des résultats
| Méthode | Erreur d’imputation (moyenne ± écart-type) | Précision de récupération (moyenne ± écart-type) | Stabilité (variance) |
|---|---|---|---|
| GRU | 3.12 ± 0.75 | 80.71 ± 4.15 | Variance élevée |
| GRU + contraintes statistiques | 2.78 ± 0.60 | 82.10 ± 4.00 | Variance modérée |
| Méthode d’imputation traditionnelle | 3.50 ± 0.90 | 75.92 ± 5.20 | Variance élevée |
| CUR-Estimator | 2.12 ± 0.35 | 89.57 ± 3.71 | Faible variance |
Interprétation : l’introduction de contraintes statistiques améliore à la fois la précision et la stabilité ; CUR-Estimator atteint les meilleures performances globales dans les scénarios d’intervalles irréguliers.
Principaux enseignements
- CUR-Estimator réduit efficacement l’accumulation d’erreurs dans les scénarios d’imputation multi-étapes.
- Les contraintes statistiques améliorent la stabilité des résultats d’imputation sous des séquences manquantes prolongées.
- La méthode fournit des résultats d’imputation plus plausibles et physiquement cohérents pour l’analyse de la dégradation des moteurs aéronautiques.
Dynamiques d’entraînement
Résultats de dix expériences sur le jeu de données C-MAPSS avec différentes méthodes, (a) MSE, (b) MAE.
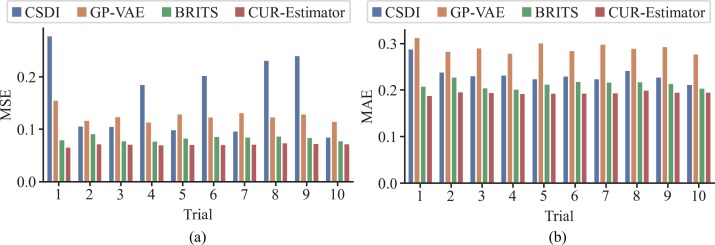
Fig. 9 : Évolution de la perte d’entraînement et de la précision d’imputation au fil du temps.
Modes d’erreur
Les matrices de confusion montrent la capacité de CUR-Estimator à imputer correctement les classes de défaillance rares.
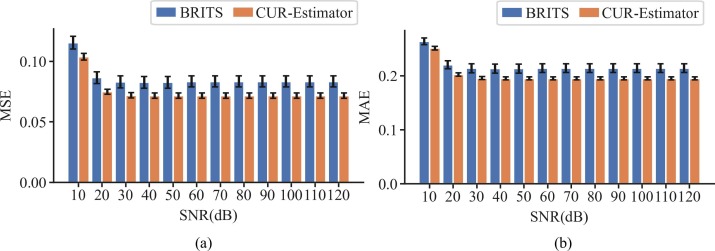
Fig. 10 : Histogrammes de la MSE et de la MAE et écarts types sous différents rapports signal/bruit.
Figures pour une lecture rapide

Référence
Si ce travail vous est utile, veuillez citer l’article.
BibTeX
@article{wu2025cur,
title = {CUR-Estimator: Towards Accurate Missing Data Imputation in Aero-Engine Degradation Processes},
author = {Wu, Haoze and Zhong, Shisheng and Zhao, Minghang and Fu, Xuyun and Zhang, Yongjian and Fu, Song},
journal = {Neurocomputing},
volume = {649},
pages = {130876},
year = {2025},
doi = {10.1016/j.neucom.2025.130876},
url = {https://doi.org/10.1016/j.neucom.2025.130876}
}Contact
Pour toute collaboration, demande d’information ou requête de reproductibilité, veuillez contacter l’auteur correspondant.
Adresse électronique
Shisheng Zhong: zhongss#hit.edu.cnMinghang Zhao: zhaomh#hit.edu.cn
Remerciements
Ce travail est soutenu par le Programme national clé de R&D de la Chine (2023YFB4302400) et la Fondation nationale des sciences naturelles de Chine (n° 92360308).