Advanced Engineering Informatics • Volume 65 • 2025 • Article 103297
Apprentissage par renforcement contrastif continu (CCRL)
Vers un agent plus robuste et sensible à l’environnement pour le diagnostic des défaillances des moteurs aéronautiques commerciaux grâce à une optimisation à long terme dans des scénarios fortement déséquilibrés.
Auteurs
Haoze Wu; Shisheng Zhong; Minghang Zhao; Xuyun Fu; Yongjian Zhang; Song Fu
Affiliations
- a. School of Mechatronics Engineering, Harbin Institute of Technology, Harbin 150001, China
- b. Department of Mechanical Engineering, Harbin Institute of Technology, Weihai 264209, China
- c. Weihai Key Laboratory of Intelligent Operation and Maintenance, Harbin Institute of Technology, Weihai 264209, China
Idée centrale
L’apprentissage par renforcement contrastif continu (CCRL) intègre une conception de récompense sensible au déséquilibre dans l’apprentissage par renforcement avec un apprentissage contrastif des représentations ne reposant pas sur la génération d’échantillons synthétiques. En attribuant une importance de récompense plus élevée aux états de défaillance rares, l’agent est guidé pour se concentrer sur des motifs de défaillance critiques lors des interactions en ligne et des mises à jour incrémentales, permettant une adaptation aux différentes phases et conditions de fonctionnement du moteur. Par ailleurs, la fonction de perte contrastive est reformulée afin d’exploiter pleinement les séries temporelles déséquilibrées existantes, en obtenant des représentations discriminantes par l’augmentation de la séparation inter-classes et la compacité intra-classe, sans introduire d’échantillons synthétiques supplémentaires.
CCRL en un coup d’œil
Pour le diagnostic des défaillances des moteurs aéronautiques dans des scénarios fortement déséquilibrés, CCRL intègre des agents guidés par l’apprentissage contrastif dans un cadre D3QN, permettant une reconnaissance stable des défaillances rares sans génération d’échantillons synthétiques, et validée par des scénarios réels et des études d’ablation.
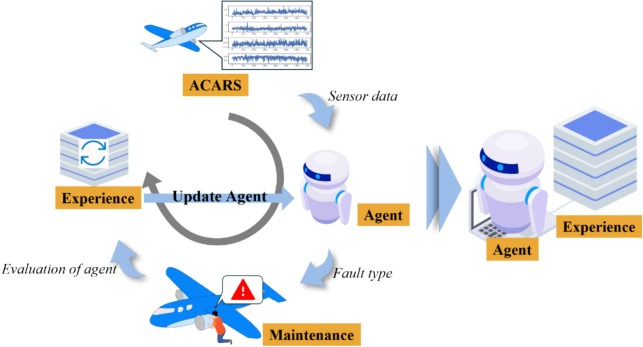
Problème
Le diagnostic des défaillances des moteurs aéronautiques est confronté à un déséquilibre sévère des classes, à la rareté des échantillons de défaillance et à des environnements de fonctionnement non stationnaires. Les méthodes traditionnelles d’apprentissage contrastif reposent sur l’augmentation de données, qui ne garantit pas la cohérence physique dans les scénarios de séries temporelles.
Idée
Améliorer la discriminabilité des caractéristiques par l’apprentissage contrastif et l’associer à un D3QN doté d’une conception de récompense sensible au déséquilibre afin d’assurer une reconnaissance stable des types de défaillance rares.
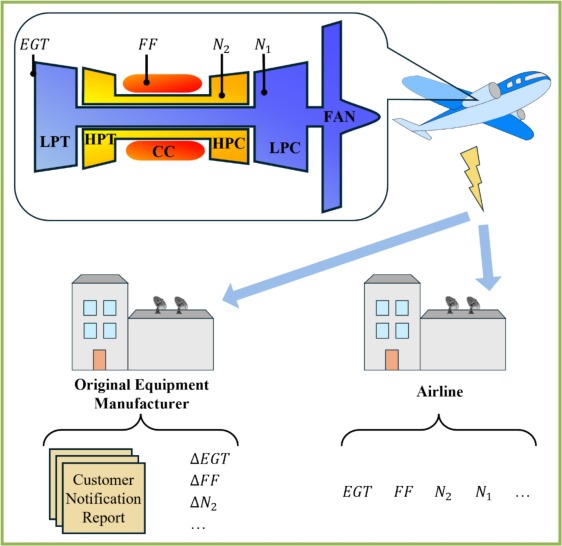
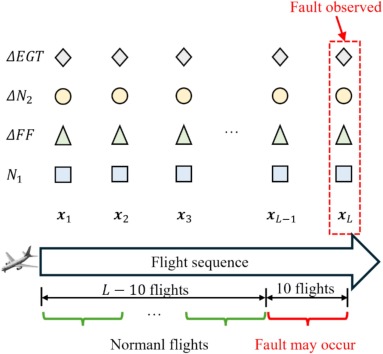
Données d’entrée
ΔEGT (écart de température des gaz d’échappement), ΔN2 (écart de vitesse du cœur), ΔFF (écart de débit de carburant) et N1 (vitesse du ventilateur) mesurés lors de la phase de décollage.
Types de défaillance
Défaillances du système VBV, défaillances EGTI, défaillances du capteur TAT et vols normaux.
Vue d’ensemble
Résumé
Bien que la stabilité des moteurs aéronautiques soit élevée, leurs défaillances peuvent entraîner des conséquences catastrophiques. En raison de la rareté des pannes, les méthodes traditionnelles de diagnostic des défaillances basées sur les données reposent sur des quantités limitées de données historiques de défaillance pour l’entraînement des modèles de classification. Elles peinent à mettre à jour les modèles en temps opportun face aux changements environnementaux et à la croissance continue des données. Pour répondre à ce problème, cet article propose une nouvelle méthode d’apprentissage automatique, à savoir l’apprentissage par renforcement contrastif continu (CCRL), qui intègre l’interaction avec l’environnement et une évolution dynamique continue pour le diagnostic des défaillances des moteurs aéronautiques dans des conditions de fort déséquilibre et de croissance continue des données. Dans un premier temps, l’environnement opérationnel de la compagnie aérienne est considéré comme l’environnement d’apprentissage de l’agent. Les données de vol de l’aéronef sont utilisées comme informations d’état fournies par l’environnement, tandis que les résultats d’identification des défaillances confirmés par le personnel au sol et les experts servent d’étiquettes pour ces états. Ce cadre garantit que l’agent peut apprendre de manière continue face à l’augmentation du volume de données. Ensuite, un encodeur d’apprentissage contrastif pour des scénarios fortement déséquilibrés est conçu, dans lequel un grand nombre d’échantillons normaux sont utilisés pour entraîner l’encodeur en construisant des paires d’échantillons positives et négatives à partir de données réelles, puis l’encodeur est affiné afin d’améliorer sa capacité à distinguer les différentes défaillances. Enfin, l’encodeur d’apprentissage contrastif est intégré dans le modèle d’apprentissage par renforcement amélioré, permettant à l’agent de mieux percevoir les changements environnementaux et de diagnostiquer les défaillances dans des scénarios fortement déséquilibrés. Une série d’expériences comparatives et d’études d’ablation menées sur des données réelles valide pleinement le potentiel d’application de la méthode proposée.
Concepts clés et expressions associées
Informations sur l’article
- Titre
- Continual contrastive reinforcement learning: Towards stronger agent for environment-aware fault diagnosis of aero-engines through long-term optimization under highly imbalance scénarios
- Revue
- Advanced Engineering Informatics
- PyPI
- ccrl
- Mots-clés
- Diagnostic des défaillances des moteurs aéronautiques ; Apprentissage par renforcement contrastif continu ; Sensibilité à l’environnement ; Croissance des données de surveillance
Pertinence pratique
- Conçu pour des opérations aériennes réelles, permettant une mise à jour continue des modèles à mesure que de nouvelles données de vol deviennent disponibles.
- Traite le déséquilibre extrême des classes sans nécessiter la génération de séries temporelles synthétiques.
- Renforce les représentations discriminantes des défaillances rares grâce à un apprentissage contrastif pondéré.
- Le façonnage de récompenses sensible au déséquilibre améliore les performances de prise de décision pour les catégories de défaillances à longue traîne.
Méthode
CCRL combine un module de distinction des caractéristiques (apprentissage contrastif avec préentraînement par autoencodeur) et un module d’identification des types (D3QN avec récompenses déséquilibrées) au sein d’un pipeline de diagnostic unifié et continuellement actualisable.
1) Boucle d’apprentissage continu sensible à l’environnement
Le processus opérationnel de la compagnie aérienne est considéré comme un environnement d’apprentissage. Après chaque vol, les données des capteurs sont transmises via ACARS et stockées. L’agent prédit le type de défaillance, lequel est évalué à l’aide des résultats confirmés par des experts, puis l’agent apprend de manière continue à partir d’une bibliothèque d’expériences en croissance afin d’atteindre une optimisation à long terme.
2) Module de distinction des caractéristiques
Contrairement aux méthodes d’augmentation de séries temporelles, CCRL construit des paires positives à partir d’échantillons réels appartenant au même type de défaillance et des paires négatives à partir d’échantillons de types de défaillance différents. Pour faire face à la rareté des échantillons de défaillance, l’encodeur est d’abord préentraîné à l’aide d’un autoencodeur LSTM sur un grand nombre d’échantillons normaux, puis affiné sous une perte contrastive pondérée afin d’apprendre des représentations discriminantes dans des contextes fortement déséquilibrés.
3) Module d’identification des types
L’encodeur contrastif figé est utilisé comme extracteur de caractéristiques et alimente un réseau Dueling Double Deep Q-Network (D3QN). Les récompenses sont mises à l’échelle en fonction de l’inverse de la fréquence des classes afin de mettre l’accent sur les défaillances rares (catégories de longue traîne), améliorant ainsi la capacité de reconnaissance des défaillances dans des conditions de déséquilibre. L’agent est entraîné à l’aide de la relecture d’expériences et d’un réseau cible pour garantir un apprentissage Q stable.
Évolution de l’apprentissage contrastif pour le diagnostic des défaillances
Dans les cadres SimCLR traditionnels, l’apprentissage contrastif repose sur l’augmentation de données pour construire des paires positives. Cependant, pour les séries temporelles des moteurs aéronautiques, aucune garantie théorique n’assure que ces augmentations préservent les caractéristiques physiques des défaillances. Ce travail étend la perte auto-supervisée standard vers une perte contrastive pondérée sensible au déséquilibre, spécifiquement conçue pour le diagnostic de défaillances fortement déséquilibrées.
Limitation : Cette perte considère tous les autres échantillons comme des négatifs équivalents et suppose implicitement un jeu de données équilibré, ce qui conduit le modèle à ignorer les défaillances rares des moteurs.
Optimisation : Introduit un poids positif pour renforcer le regroupement des défaillances rares et un poids négatif pour réduire l’interférence de la classe dominante « normale ».
Description des symboles
- Facteur de mise à l’échelle de température pour les logits de similarité.
- Similarité cosinus entre les vecteurs latents z_i et z_j.
- Poids des paires positives visant à mettre en évidence les défaillances rares.
- Poids des paires négatives permettant de réduire l’influence des classes dominantes (par exemple, l’état normal).
- Nombre de paires d’ancrage positives dans un lot.
Détails d’implémentation technique :
- Cohérence physique : Plutôt que d’utiliser des augmentations synthétiques, des échantillons réels distincts appartenant au même type de défaillance sont appariés, garantissant que le modèle apprend des motifs réels des capteurs.
- Préentraînement de l’encodeur : Un autoencodeur LSTM est d’abord entraîné sur un grand volume de données normales afin de capturer les dynamiques de base du moteur, avant un affinage sous la perte pondérée.
- Distinction des caractéristiques : En définissant des poids distincts, le modèle privilégie la séparation des catégories de défaillances fortement déséquilibrées (VBV, EGTI, TAT).
Figure : module de distinction des caractéristiques
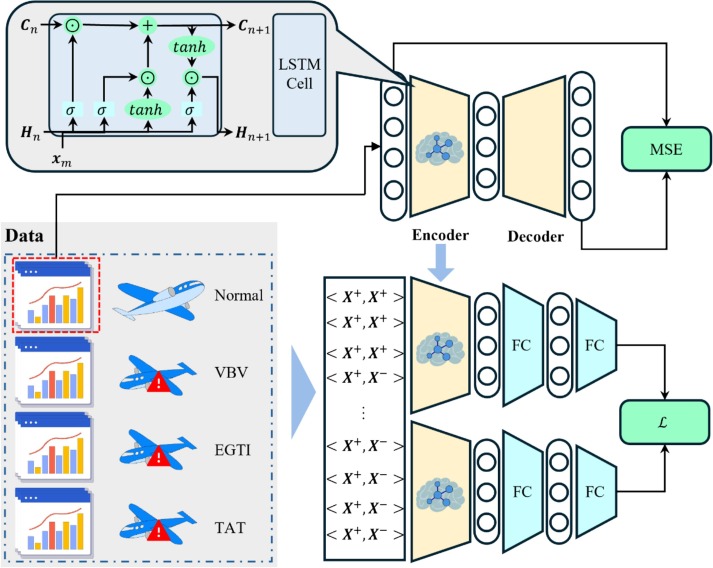
Fig. 3 : Pipeline de préentraînement par autoencodeur et d’apprentissage contrastif pondéré.
Signaux et types de défaillance
Entrées
ΔEGT, ΔN2, ΔFF et N1 sur une fenêtre temporelle de 10 vols.
Classes
Normal, défaillance du système VBV, EGTI, défaillance du capteur TAT.
Objectif de déploiement
Diagnostic robuste des défaillances des moteurs aéronautiques sous déséquilibre extrême des classes, avec adaptation continue à des environnements opérationnels évolutifs.
Résultats
CCRL est évalué en comparaison avec des méthodes de base D3QN utilisant le sous-échantillonnage (DS) et le sur-échantillonnage (OS) dans des conditions de divisions aléatoires répétées. L’objectif principal est de réaliser un diagnostic robuste des défaillances des moteurs aéronautiques sous déséquilibre extrême des classes, la capacité d’adaptation continue constituant un objectif secondaire.
F1 global
84.26 ± 4.62
Meilleure performance F1 globale obtenue sur des expériences répétées.
Précision
87.19 ± 4.34
Réduction significative des fausses alertes dans des conditions déséquilibrées.
Rappel
84.00 ± 4.77
Capacité accrue de reconnaissance des classes minoritaires.
Éléments validés
- Diagnostic déséquilibré: La capacité de diagnostic pour les catégories de défaillance à longue traîne est confirmée.
- Sans échantillons supplémentaires: Amélioration des performances sans augmentation de la quantité de données.
- Stabilité: Variance des performances plus faible sur des divisions aléatoires répétées.
- Validité architecturale: Les expériences d’ablation confirment la pertinence de chaque module proposé.
Configuration expérimentale
Tâche
Diagnostic multi-classes des défaillances des moteurs aéronautiques sous déséquilibre sévère des classes (défaillances à longue traîne face à un grand nombre d’échantillons normaux).
Méthodes de référence
D3QN, DS + D3QN, OS + D3QN (divisions aléatoires répétées).
Indicateurs d’évaluation
F1, précision et rappel (moyenne ± écart-type), avec un accent particulier sur les performances des classes minoritaires.
Conclusion clé validée
Meilleure séparabilité des défaillances et apprentissage décisionnel sous déséquilibre extrême ; l’évolution continue constitue une contribution secondaire.
Tableau des résultats
| Méthode | F1 (moyenne ± écart-type) | Précision (moyenne ± écart-type) | Rappel (moyenne ± écart-type) |
|---|---|---|---|
| D3QN | 77.19 ± 3.81 | 80.71 ± 4.15 | 76.75 ± 3.88 |
| DS + D3QN | 68.15 ± 9.26 | 71.05 ± 9.10 | 68.00 ± 9.14 |
| OS + D3QN | 74.38 ± 5.07 | 81.20 ± 3.66 | 74.00 ± 4.90 |
| CCRL | 84.26 ± 4.62 | 87.19 ± 4.34 | 84.00 ± 4.77 |
Interprétation : le sous-échantillonnage dégrade les performances en raison de la perte d’information ; le sur-échantillonnage améliore le rappel mais manque de stabilité ; CCRL atteint le meilleur équilibre global.
Principaux enseignements
- CCRL améliore significativement la reconnaissance des défaillances des classes minoritaires sans augmenter la quantité d’échantillons.
- Une précision plus élevée implique moins de fausses alertes dans les déploiements industriels.
- Une variabilité plus faible indique une robustesse accrue face aux divisions aléatoires.
Résultats des expériences d’ablation
- Apprentissage contrastif des caractéristiques Renforce significativement la séparabilité des classes dans des contextes déséquilibrés.
- Mécanisme de récompense déséquilibrée Stabilise l’apprentissage décisionnel pour les défaillances rares.
- Pipeline complet Le cadre CCRL complet présente les meilleures performances et la meilleure stabilité.
Dynamiques d’entraînement
Par rapport aux méthodes de référence DS et OS, CCRL présente une convergence plus régulière et une évolution des récompenses plus stable.
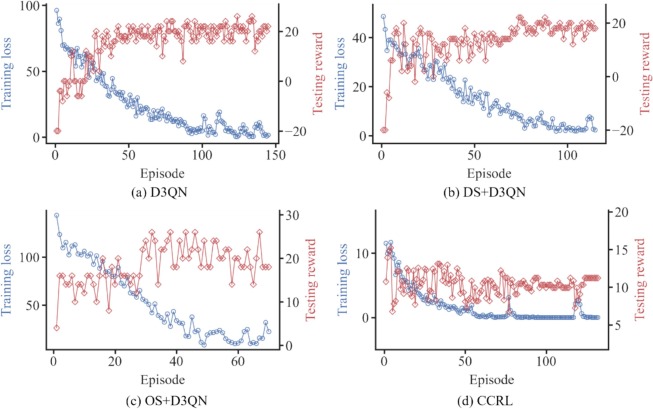
Fig. 12 : Perte d’entraînement et récompenses de test pour différentes méthodes.
Modes d’erreur
Les matrices de confusion montrent que les méthodes de référence confondent plus facilement les défaillances rares avec l’état normal, tandis que CCRL atténue nettement ce problème.
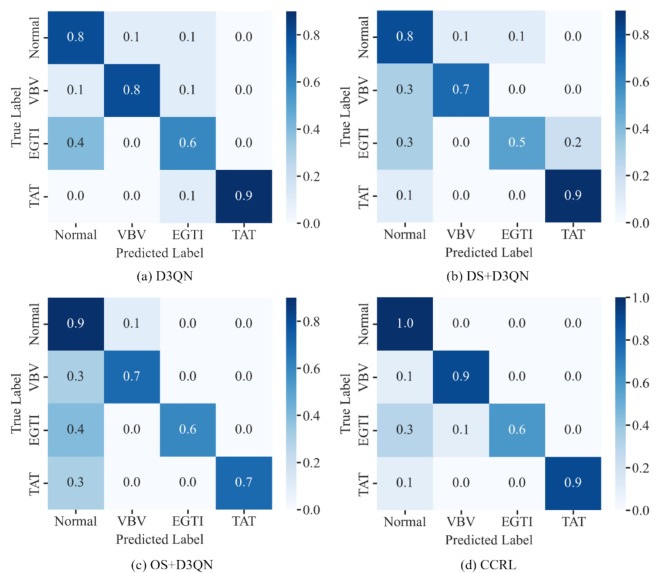
Fig. 15 : Les matrices de confusion illustrent les erreurs de classification des défaillances rares.
Figures pour une lecture rapide
Impact et citations
Travaux représentatifs citant, prolongeant ou s’alignant conceptuellement avec l’apprentissage par renforcement contrastif continu pour le diagnostic des défaillances dans des environnements déséquilibrés et non stationnaires.
Advanced Engineering Informatics
A fault diagnosis data augmentation method integrating multimodal non-Gaussian denoising diffusion generative adversarial network
Dans les environnements industriels réels, l’acquisition de données de défaillance est bien plus difficile que celle des données d’état sain. En conséquence, les petits échantillons et le déséquilibre sévère des classes sont devenus des défis centraux du diagnostic de défaillance.
Energy
Propagation and évolution graph method embedded with physical constraints for multi-factor coupled deep fault diagnosis in aero-engines
Wu et al. ont combiné l’apprentissage par transfert profond, l’apprentissage par renforcement et l’apprentissage par renforcement contrastif continu afin de réaliser le diagnostic des défaillances des moteurs aéronautiques et l’optimisation des stratégies de maintenance.
Mathematics
Aviation Fuel Pump Fault Diagnosis Based on Conditional Variational Self-Encoder Adaptive Synthetic Less Data Enhancement
Le déséquilibre des classes biaise les modèles d’apprentissage supervisé en faveur des classes majoritaires, entraînant une mauvaise reconnaissance des classes minoritaires, des taux élevés de fausses alertes et des frontières de décision peu claires.
Measurement
Feature alignment and spatio-temporal domain adaptive strategy for aeroengine virtual sensor model construction under domain shifts
Wu et al. ont développé un cadre de modélisation de substitut robuste ciblant des environnements de données fortement déséquilibrés, en mettant l’accent sur l’adaptation de domaine et l’alignement des représentations.
IEEE Transactions on Instrumentation and Measurement
An Effective Framework for Cross-Condition Fault Diagnosis of Gearboxes Under Class Imbalance
En intégrant l’apprentissage contrastif dans l’apprentissage par renforcement, l’agent perçoit mieux les changements environnementaux et améliore la robustesse du diagnostic sous déséquilibre des classes.
Journal of Mechanical Engineering and Sciences
Development of an intelligent jet engine controller using a model-based deep deterministic policy gradient technique
Les techniques d’apprentissage par renforcement, y compris l’apprentissage contrastif continu et le filtrage adaptatif, renforcent la détection des défaillances des moteurs aéronautiques dans des conditions de fort déséquilibre et de changements opérationnels brusques.
Référence
Si ce travail vous est utile, veuillez citer l’article.
BibTeX
@article{wu2025ccrl,
title = {Continual contrastive reinforcement learning: Towards stronger agent for environment-aware fault diagnosis of aero-engines through long-term optimization under highly imbalance scenarios},
author = {Wu, Haoze and Zhong, Shisheng and Zhao, Minghang and Fu, Xuyun and Zhang, Yongjian and Fu, Song},
journal = {Advanced Engineering Informatics},
volume = {65},
pages = {103297},
year = {2025},
doi = {10.1016/j.aei.2025.103297},
url = {https://doi.org/10.1016/j.aei.2025.103297}
}Contact
Pour toute collaboration, demande d’information ou requête de reproductibilité, veuillez contacter les auteurs correspondants.
Adresse électronique
Shisheng Zhong: zhongss#hit.edu.cnMinghang Zhao: zhaomh#hit.edu.cn
Remerciements
Ce travail est soutenu par le Programme national clé de R&D de la Chine (2023YFB4302400).