Advanced Engineering Informatics • Volume 65 • 2025 • Article 103297
Continual contrastive reinforcement learning (CCRL)
Towards a stronger, environment-aware agent for commercial aero-engine fault diagnosis through long-term optimization under highly imbalanced scenarios.
Authors
Haoze Wu; Shisheng Zhong; Minghang Zhao; Xuyun Fu; Yongjian Zhang; Song Fu
Affiliations
- a. School of Mechatronics Engineering, Harbin Institute of Technology, Harbin 150001, China
- b. Department of Mechanical Engineering, Harbin Institute of Technology, Weihai 264209, China
- c. Weihai Key Laboratory of Intelligent Operation and Maintenance, Harbin Institute of Technology, Weihai 264209, China
Core Idea
Continual contrastive reinforcement learning (CCRL) integrates imbalance-aware reward design in reinforcement learning with contrastive representation learning that does not rely on synthetic sample generation. By assigning higher reward importance to rare fault states, the agent is guided to focus on critical fault patterns during online interaction and incremental updates, and also to adapt to changes in engine operating stages and conditions. Meanwhile, the contrastive loss is reformulated to fully exploit existing imbalanced time-series data, achieving discriminative representations by enlarging inter-class separation and compacting intra-class structure without introducing additional synthetic samples.
CCRL at a glance
For aero-engine fault diagnosis under highly imbalanced scenarios, CCRL integrates a contrastive learning-driven agent into a D3QN framework. By leveraging feature distinction without synthetic sample generation and an imbalance-aware reward mechanism, it achieves stable and effective fault recognition, which is validated through real-world diagnostic scenarios and ablation studies.
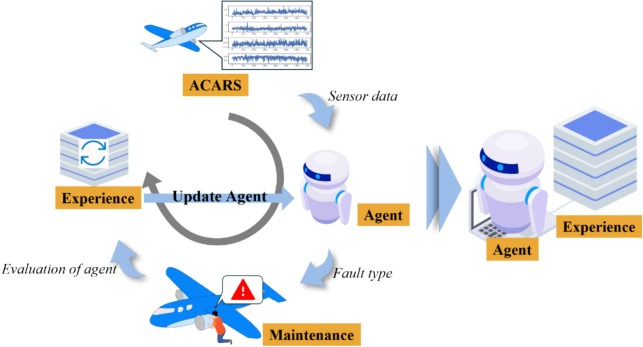
Problem
Aero-engine fault diagnosis faces severe class imbalance, scarce fault samples, and nonstationary operating environments. Traditional contrastive learning methods rely on data augmentation, which lacks physical consistency guarantees in time-series scenarios.
Idea
Enhance feature discriminability via contrastive learning and combine it with D3QN equipped with imbalance-aware reward design for stable recognition of rare fault types.
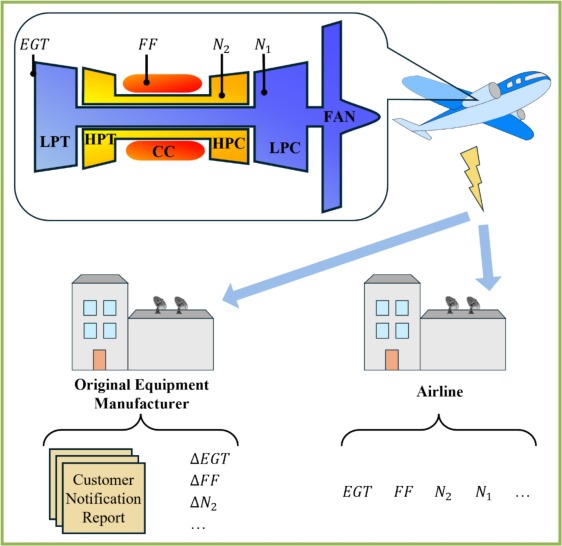
Input data
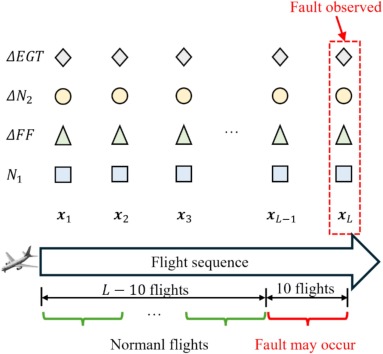
ΔEGT (exhaust gas temperature deviation), ΔN2 (core speed deviation), ΔFF (fuel flow deviation), and N1 (fan speed) measured at the takeoff stage.
Fault types
VBV system faults, EGTI faults, TAT sensor faults, and normal flights.
Overview
Abstract
Although the stability of aero-engines is high, their failures can lead to catastrophic consequences. Due to the infrequent nature of faults, traditional data-driven fault diagnosis methods rely on limited amounts of historical failure data for training classification models. They cannot update models on time in response to environmental changes and data growth. To address the issue, this paper proposes a new machine learning method, i.e., Continual Contrastive Reinforcement Learning (CCRL), that integrates environmental interaction and continual dynamic evolution for fault diagnosis of aero-engine under conditions of high imbalance and continually growing data. First, the operating environment of the airline is treated as the learning environment for the agent. The aircraft’s flight data is used as the state information provided by the environment, while the failure identification results from ground personnel and experts serve as the labels for this state information. This framework ensures the agent can continually learn in the face of increasing data volumes. Next, a contrastive learning encoder for highly imbalanced scenarios is designed, where a large number of normal samples are used to train an encoder that constructs positive and negative sample pairs with actual data, fine-tuning the encoder to improve its ability to distinguish different faults, thereby designing a contrastive learning encoder suitable for highly imbalanced scenarios. Finally, the contrastive learning encoder is embedded into the enhanced learning model, enabling the agent to better perceive environmental changes and diagnose failures under highly imbalanced scenarios. This paper conducts a series of contrastive and ablation experiments using real data, which fully validate the application potential of the proposed method.
Key concepts and searchable phrases
Paper details
- Title
- Continual contrastive reinforcement learning: Towards stronger agent for environment-aware fault diagnosis of aero-engines through long-term optimization under highly imbalance scenarios
- Journal
- Advanced Engineering Informatics
- PyPI
- ccrl
- Keywords
- Aero-engine fault diagnosis; Continual contrastive reinforcement learning; Environment awareness; Monitoring data growth
Practical relevance
- Designed for real airline operations, enabling continual model updates as new flight data arrive.
- Addresses extreme class imbalance without requiring synthetic time-series generation.
- Enhances discriminative representations of rare faults through weighted contrastive learning.
- Imbalance-aware reward shaping improves decision-making performance for long-tail fault categories.
Method
CCRL combines a feature distinction module (contrastive learning with autoencoder pretraining) and a type identification module (D3QN with imbalanced rewards) in an end-to-end, continually updatable pipeline.
1) Environment-aware continual learning loop
The airline operating process is treated as an environment. After each flight, sensor data is transmitted via ACARS and stored. The agent predicts fault type and is evaluated against expert-confirmed outcomes, then learns continually from the growing experience library for long-term optimization.
2) Feature distinction module
Instead of relying on time-series augmentation, CCRL constructs positive pairs from different samples of the same fault type and negative pairs from different fault types. To cope with scarce fault samples, the encoder is pretrained using an LSTM autoencoder on abundant normal samples, then fine-tuned under a weighted contrastive loss to learn discriminative representations in highly imbalanced settings.
3) Type identification module
The frozen contrastive encoder feeds a Dueling Double Deep Q-Network (D3QN). Rewards are scaled by inverse class frequency to emphasize rare faults (long-tail classes), improving fault recognition under imbalance. The agent is trained with experience replay and a target network for stable Q-learning.
Evolution of Contrastive Learning for Fault Diagnosis
In traditional SimCLR frameworks, contrastive learning relies on data augmentation to construct positive pairs. However, for aero-engine time-series data, there is no theoretical guarantee that such augmentations preserve the physical characteristics of faults. This work extends the standard self-supervised loss toward an imbalance-aware weighted contrastive loss tailored for highly imbalanced fault diagnosis.
Limitation: It treats all other samples as equal negatives and assumes a balanced dataset, which causes the model to overlook rare engine faults.
Optimization: Introduces (positive weight) to enhance clustering of rare faults and (negative weight) to reduce interference from the dominant "Normal" class.
Symbol notes
- Temperature scaling factor for similarity logits.
- Cosine similarity between latent vectors z_i and z_j.
- Positive-pair weight to emphasize rare faults.
- Negative-pair weight to down-weight dominant classes (e.g., Normal).
- Number of positive anchor pairs in a batch.
Technical Implementation Details:
- Physical Consistency: Instead of synthetic augmentations, different real samples of the same fault type are paired together, ensuring the model learns actual sensor patterns.
- Encoder Pre-training: An LSTM-Autoencoder is first trained on abundant normal data to capture baseline engine dynamics before fine-tuning with the weighted loss.
- Feature Distinction: By setting appropriate weights, the model prioritizes the separation of highly imbalanced fault categories (VBV, EGTI, TAT).
Figure: Feature distinction module
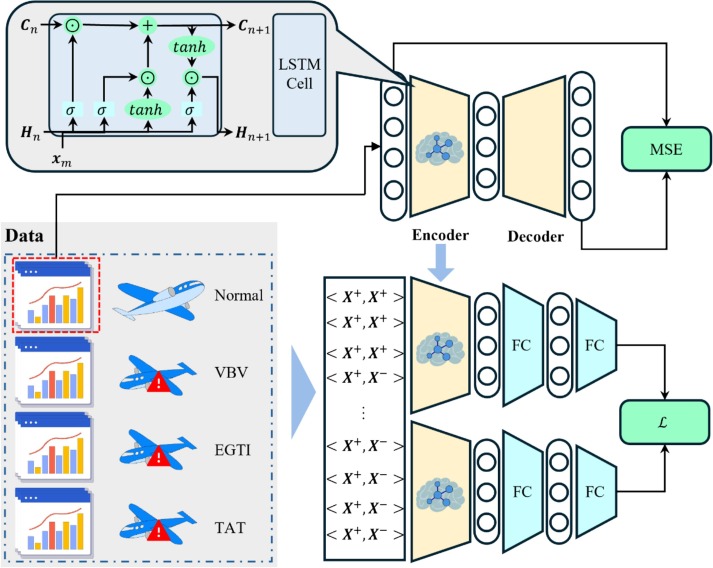
Fig. 3: Autoencoder pretraining + weighted contrastive learning pipeline.
Signals and fault types
Inputs
Delta EGT, Delta N2, Delta FF, N1 over a 10-flight window (time series).
Classes
Normal, VBV system failure, EGTI, TAT sensor failure.
Deployment intent
Robust aero-engine fault diagnosis under extreme class imbalance, with continual adaptation to gradually evolving operating environments.
Results
CCRL is evaluated against D3QN baselines with down-sampling (DS) and over-sampling (OS) under repeated random splits. The primary objective is robust aero-engine fault diagnosis under extreme class imbalance; continual adaptation is a secondary capability.
Headline (F1)
84.26 ± 4.62
Best overall F1 across repeated runs.
Precision
87.19 ± 4.34
Fewer false alarms under imbalance.
Recall
84.00 ± 4.77
Better minority-class recognition.
What was validated
- Imbalanced diagnosis: long-tail fault categories are the core challenge.
- No extra samples: improvement without increasing sample quantity.
- Stability: lower variance across repeated random splits.
- Architectural validity: Ablation studies confirm the rationality of each proposed module.
Experimental setup
Task
Multi-class aero-engine fault diagnosis under severe class imbalance (long-tail faults vs. abundant normal).
Baselines
D3QN, DS + D3QN, OS + D3QN (repeated random splits).
Metrics
F1, Precision, Recall (mean ± std), emphasizing minority-class performance.
Key claim validated
Better fault separability and decision learning under extreme imbalance; continual evolution is secondary.
Results Table
| Method | F1 (mean ± std) | Precision (mean ± std) | Recall (mean ± std) |
|---|---|---|---|
| D3QN | 77.19 ± 3.81 | 80.71 ± 4.15 | 76.75 ± 3.88 |
| DS + D3QN | 68.15 ± 9.26 | 71.05 ± 9.10 | 68.00 ± 9.14 |
| OS + D3QN | 74.38 ± 5.07 | 81.20 ± 3.66 | 74.00 ± 4.90 |
| CCRL | 84.26 ± 4.62 | 87.19 ± 4.34 | 84.00 ± 4.77 |
Interpretation: DS harms performance due to information loss; OS improves recall but is less stable. CCRL achieves the best balance.
Key takeaways
- CCRL improves minority-class fault recognition without increasing sample quantity.
- Higher precision indicates fewer false alarms in operational deployment.
- Lower variability suggests stronger robustness across random splits.
Ablation findings
- Contrastive feature learning strengthens class separability under imbalance.
- Imbalance-aware rewards stabilize decision learning for rare faults.
- Full pipeline The full CCRL pipeline achieves the strongest performance and stability.
Training dynamics
CCRL shows smoother convergence and more stable reward progression compared with DS/OS baselines.
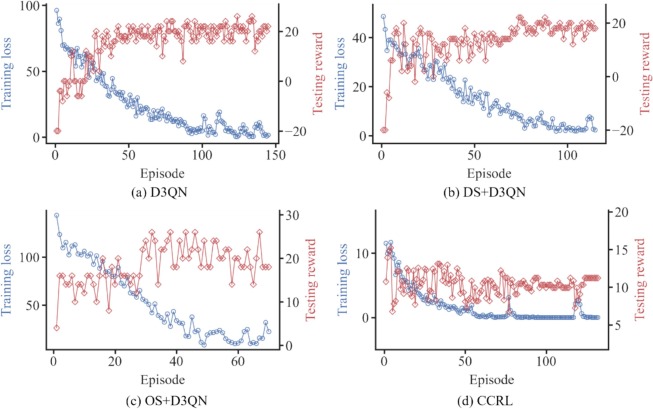
Fig. 12: Training loss and test rewards across methods.
Error patterns
Confusion matrices highlight where baselines confuse rare faults with normal, while CCRL reduces this failure mode.
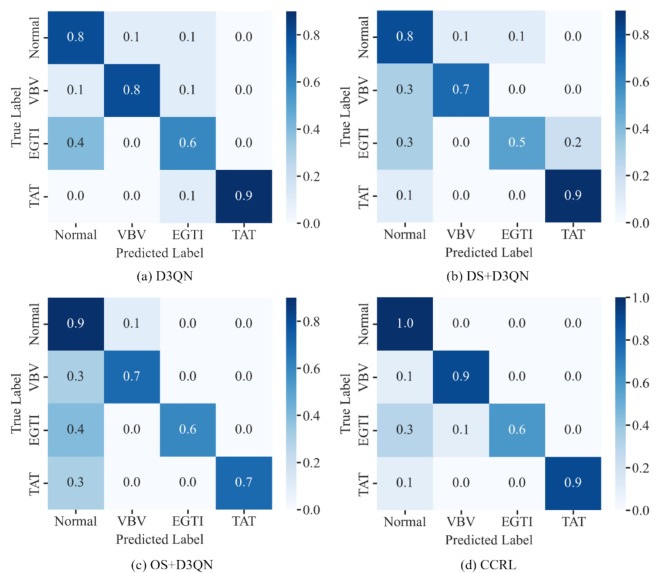
Fig. 15: Confusion matrices show where methods confuse rare faults with normal.
Figures for a quick read
How this work is cited and extended
Representative studies that cite, extend, or conceptually align with continual contrastive reinforcement learning for fault diagnosis under class imbalance and nonstationary environments.
Advanced Engineering Informatics
A fault diagnosis data augmentation method integrating multimodal non-Gaussian denoising diffusion generative adversarial network
In real-world industrial environments, collecting fault data is far more difficult than acquiring healthy-state data. As a result, small sample sizes and severe class imbalance have become central challenges in fault diagnosis.
Energy
Propagation and evolution graph method embedded with physical constraints for multi-factor coupled deep fault diagnosis in aero-engines
Wu et al. utilized deep transfer learning, reinforcement learning, and continual contrastive reinforcement learning to achieve aero-engine fault diagnosis and maintenance strategy optimization.
Mathematics
Aviation Fuel Pump Fault Diagnosis Based on Conditional Variational Self-Encoder Adaptive Synthetic Less Data Enhancement
Class imbalance biases supervised learning models toward majority classes, leading to poor minority-class recognition, high false-alarm rates, and unclear decision boundaries.
Measurement
Feature alignment and spatio-temporal domain adaptive strategy for aeroengine virtual sensor model construction under domain shifts
Wu et al. developed a robust surrogate modeling framework targeting highly imbalanced data environments, emphasizing domain adaptation and representation alignment.
IEEE Transactions on Instrumentation and Measurement
An Effective Framework for Cross-Condition Fault Diagnosis of Gearboxes Under Class Imbalance
By embedding contrastive learning into reinforcement learning, the agent better perceives environmental changes and improves diagnostic robustness under class imbalance.
Journal of Mechanical Engineering and Sciences
Development of an intelligent jet engine controller using a model-based deep deterministic policy gradient technique
Reinforcement learning techniques, including continual contrastive learning and adaptive filtering, enhance aero-engine fault detection during periods of high imbalance and sudden operational changes.
Citation
If this work is useful, please cite the paper.
BibTeX
@article{wu2025ccrl,
title = {Continual contrastive reinforcement learning: Towards stronger agent for environment-aware fault diagnosis of aero-engines through long-term optimization under highly imbalance scenarios},
author = {Wu, Haoze and Zhong, Shisheng and Zhao, Minghang and Fu, Xuyun and Zhang, Yongjian and Fu, Song},
journal = {Advanced Engineering Informatics},
volume = {65},
pages = {103297},
year = {2025},
doi = {10.1016/j.aei.2025.103297},
url = {https://doi.org/10.1016/j.aei.2025.103297}
}Contact
For collaboration, inquiries, or reproducibility requests, please contact the corresponding authors.
Contact Email
Shisheng Zhong: zhongss#hit.edu.cnMinghang Zhao: zhaomh#hit.edu.cn
Acknowledgment
Supported by National Key R&D Program of China (2023YFB4302400).